如今,大语言模型已经能写文章、编代码、回答问题,展现出惊人的语言理解能力。但在医疗、金融、法律等专业领域,再强大的大模型也常常“犯难”——因为这些领域的文本中,藏着大量普通人看不懂的专有名词、行业术语和缩写,而这些内容往往不在模型的训练数据里。
比如,让大模型去阅读一份医疗机构的运营数据,里面可能有科室缩写、药品名称、内部流程术语,模型看不太懂,自然也就标不准。
更麻烦的是,这类专业文本的标注本身就很困难:懂行的专家数量有限,能标注的数据极少;而待标注的数据量又非常庞大,光靠人工根本忙不过来。这就形成了一个典型的“两难”困境。
针对这个问题,合肥高维数据技术有限公司的一项发明专利《基于大语言模型的特定领域文本分类标注方法及系统》提出了一套新的解决方案。简单来说,这套方案的核心思路是:不要只让大模型“硬猜”,而是教会它“问路”。
给大模型配一套“工具箱”
研究人员为大语言模型设计了一套专门的“调用接口”,就像给它配了一个工具箱。这套接口以交互对话方式设计——模型可以像人一样“主动开口”选择需要哪个工具,而每个工具返回的结果也以对话形式反馈给模型,充分利用了大语言模型强大的对话理解和记忆能力。
这套“工具箱”包含七个专用接口:
精确查询接口:遇到不懂的词,可以精确查询领域内专有词汇的含义,就像查阅专业词典;
模糊查询接口:如果精确查不到,还可以模糊匹配,返回相近的词语及其含义;
词汇添加接口:查到了新词,可以把它及其解释添加到专有词汇表中,下次就不再陌生;
同表查询接口:可以查看同一个表格中其他字段的数据及其标注结果,从整体上理解表格语义;
字段查询接口:可以查询字段名称相似的文本数据及其标注结果,通过类比推断真实含义;
未知词汇接口:实在无法判断的词汇,就添加到“未知含义词汇表”,留待专家解释;
标注输出接口:最终通过这个接口给出分类标注结果,或者给出“无法分类”的结论。
这套工具箱的逻辑很清晰:不让模型在不懂的时候硬猜,而是给它一套完整的查询、学习、记录、反馈机制。遇到生词就去查,查到了就记下来,查不到就标记出来交给专家。
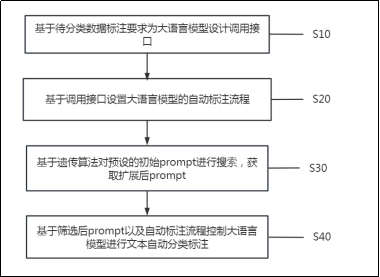
基于大语言模型的特定领域文本分类标注方法的流程示意图
给大模型设计一套“工作流程”
有了工具还不够,还得教会它怎么用。这套方案为大语言模型设计了一套完整的自动标注流程:
先初始化专有词汇表,把领域内的专有词语都加进去 → 尝试给出文本分类标注结果 → 判断文本中是否包含不理解的词语 → 遇到不懂的词,先精确查询,查不到就模糊查询 → 再看看同表中其他数据是怎么标注的 → 再看看字段相似的数据是怎么标注的 → 根据查询结果判断能否确定词语含义,能确定的就添加到专有词汇表,实在确定不了的就记入“未知词汇表”。
专家可以定期查看“未知词汇表”,对里面的词语进行解释后,重新添加到专有词汇库中。同时,之前分类失败的数据也会被重新拿出来,让已经“学到新知识”的模型再试一次。这样一轮一轮下来,模型越标越准,越标越熟练。
帮大模型找到最优“指令”
用过ChatGPT的人都知道,同样的任务,换一种问法(也就是prompt),得到的答案质量可能天差地别。这套方案引入了一种基于遗传算法的自动搜索方法,可以在大量候选prompt中,自动找到效果最好的那一个。更巧妙的是,算法还设置了“遗传次数惩罚”——避免搜索结果局限在少数几个prompt里出不来,保证能找到更优的解。
技术优势
与传统方法相比,这套技术有几个实实在在的优点:
✅️减少对专家的依赖:以往需要专家标注大量数据才能训练模型,现在只需要少量专家标注数据,系统就可以启动自动标注流程;
✅️提升标注准确率:通过查询接口、流程设计和prompt优化,模型在专业领域的分类准确率显著提高;
✅️越用越好用:系统具备知识积累能力,专有词汇表不断丰富,标注效果会随着使用而持续改进。
简单来说,这套方案不是让大语言模型变得更“聪明”,而是让它学会在遇到不懂的内容时,知道去哪里查、怎么问、怎么学——这种能力,恰恰是处理专业文本最需要的。
应用场景
该技术可广泛应用于医疗文本分类、金融报告分析、企业内部数据治理、法律文书处理等专业场景,帮助专业机构、企业将专家从繁重的重复性标注工作中解放出来,专注于更高价值的核心业务。
医疗文本分类:自动识别病历、影像报告中的专业术语,将海量非结构化文本归入对应病种与等级,辅助科研数据提取与临床决策。
金融报告分析:智能分类研报、公告与合同条款,识别合规风险与投资主题,构建动态知识库,提升投研与风控效率。
企业内部数据治理:统一分类内部文档、邮件与沟通记录,构建企业知识图谱,支撑合规审查与业务流程自动化。
法律文书处理:快速解析起诉状、裁判文书,实现智能分案与合规审查,辅助法务人员高效定位关键条款与风险点。
在大模型技术蓬勃发展的今天,如何让通用大模型更好地服务于垂直行业,是产业落地面临的关键课题。合肥高维数据技术有限公司的这一创新成果,为特定领域文本标注提供了高效、智能的解决方案,也为大语言模型在专业场景的深度应用开辟了新路径。
技术交流与合作洽谈:请致电 0551-67122296
- END -